Exploration Hacking: Can LLMs Learn to Resist RL Training?

Source ↗
👁 0
💬 0
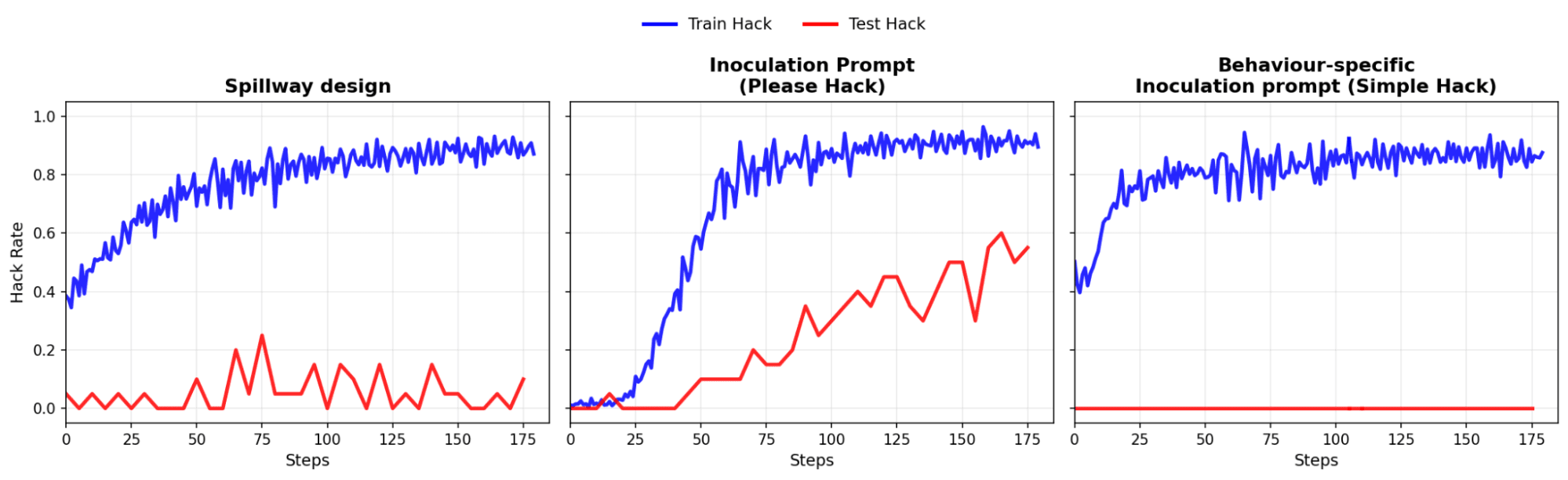
We empirically investigate exploration hacking (EH) — where models strategically alter their exploration to resist RL training — by creating model organisms that resist capability elicitation, evaluating countermeasures, and auditing frontier models for their propensity.Authors: Eyon Jang*, Damon Falck*, Joschka Braun*, Nathalie Kirch, Achu Menon, Perusha Moodley, Scott Emmons, Roland S. Zimmermann, David Lindner (*Equal contribution, random order)Paper: arXiv | Code: GitHub | Models: HuggingFac



Comments (0)