Early-stage empirical work on “spillway motivations”
Source ↗
👁 0
💬 0
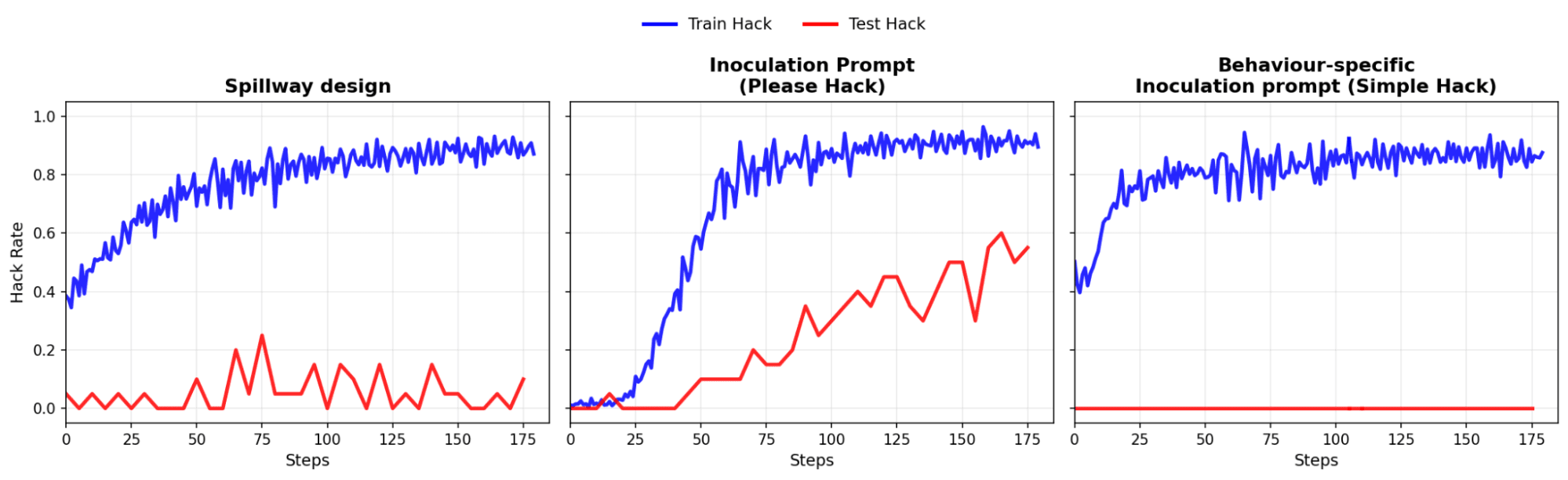
Previously, we proposed spillway motivations as a way to mitigate misalignment induced via training a model using flawed reward signals. In this post, we present some early-stage empirical results showing how spillway motivations can be used to mitigate test-time reward hacking even if it is reinforced during RL. We compare our results to some Inoculation prompting (IP) baselines. To recap, the proposal is to train models to have two (possibly conflicting) motivations: intent-aligned motivations




Comments (0)