Scaffolding vs Reinforcement Finetuning for AI Forecasting
Source ↗
👁 0
💬 0
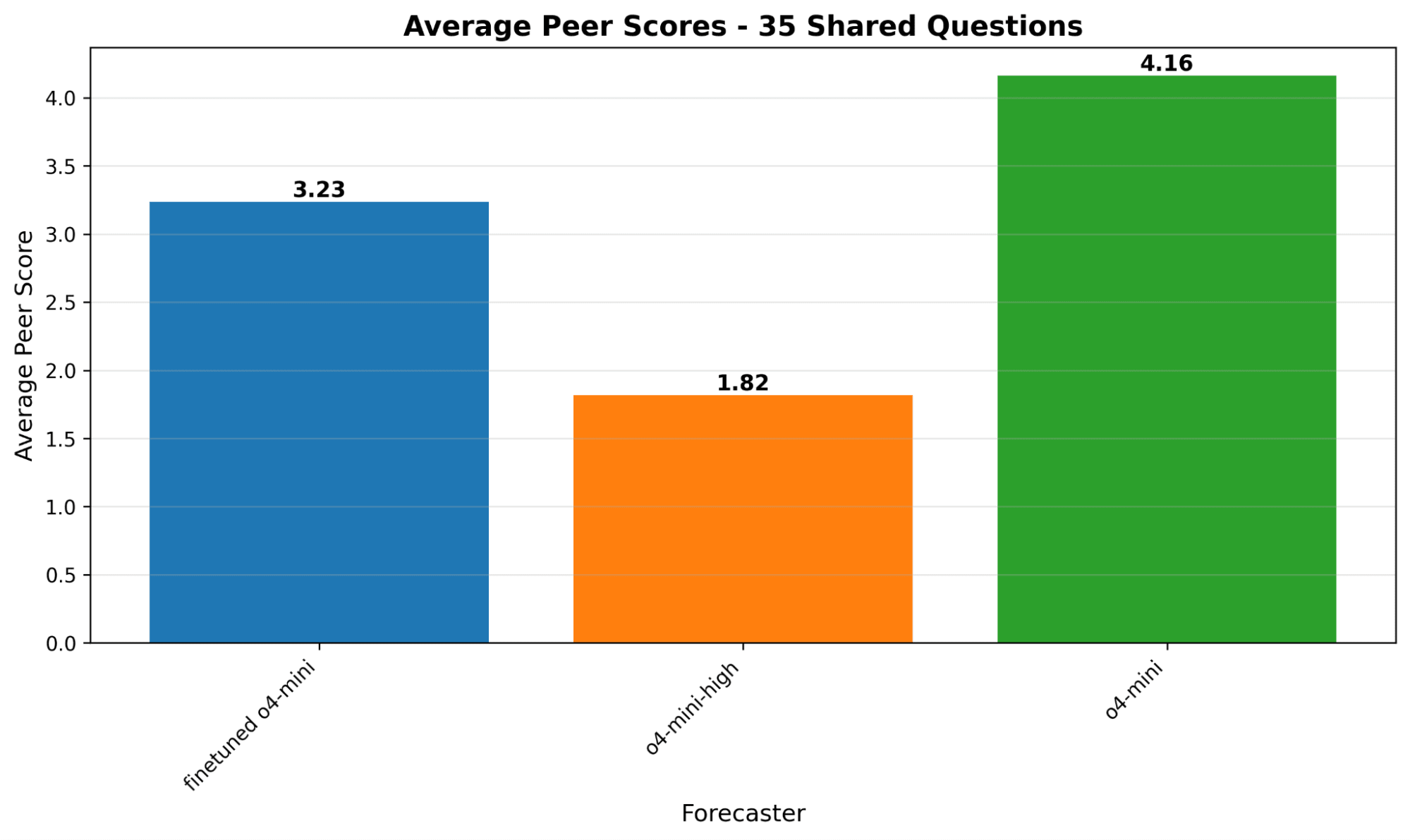
Epistemic status: low-medium confidence in results, this is work I did last year and has a low sample size. However I think the takeaways are still accurate.I built a forecasting bot using OpenAI’s Reinforcement Finetuning and a multi-agent architecture, then tested it against simpler baselines in a metaculus tournament. The aggregate scores favored the baseline, but when I broke down results by question type, the finetuned model outperformed on numeric questions (average +14.59 vs +9.25 using M


Comments (0)