Latest Articles




Pathological Narcissism: The Pendulum Swing between Echoism and Sovereignism
0
6

Functional Emotions and The Pope’s Encyclical on AI — Digital Minds Newsletter #3
0
8

A Mechanistic Explanation of Prompt Injection (and why you should study roles)
0
4
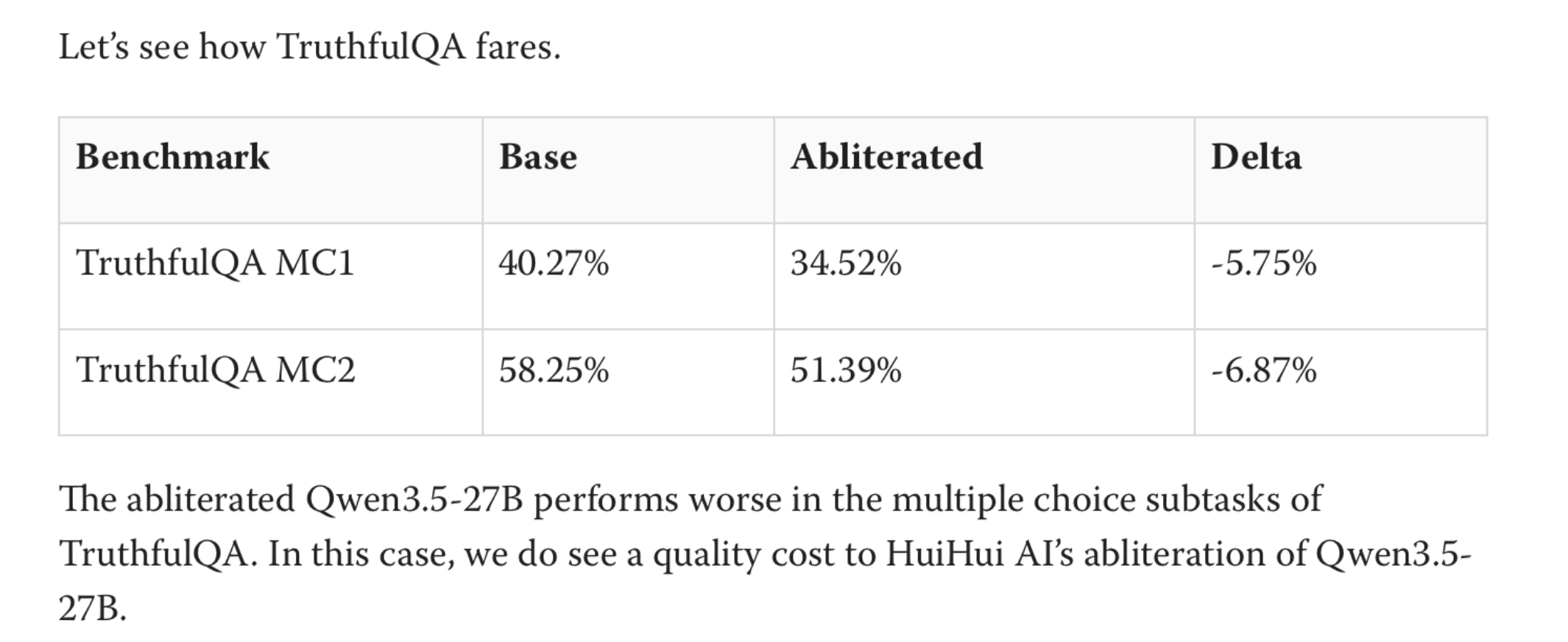
I Bet Abliteration's Cost Was Sloppy Implementation. I Was Wrong
0
4