Can activation verbalizers surface an internal chain of thought?
Source ↗
👁 0
💬 0
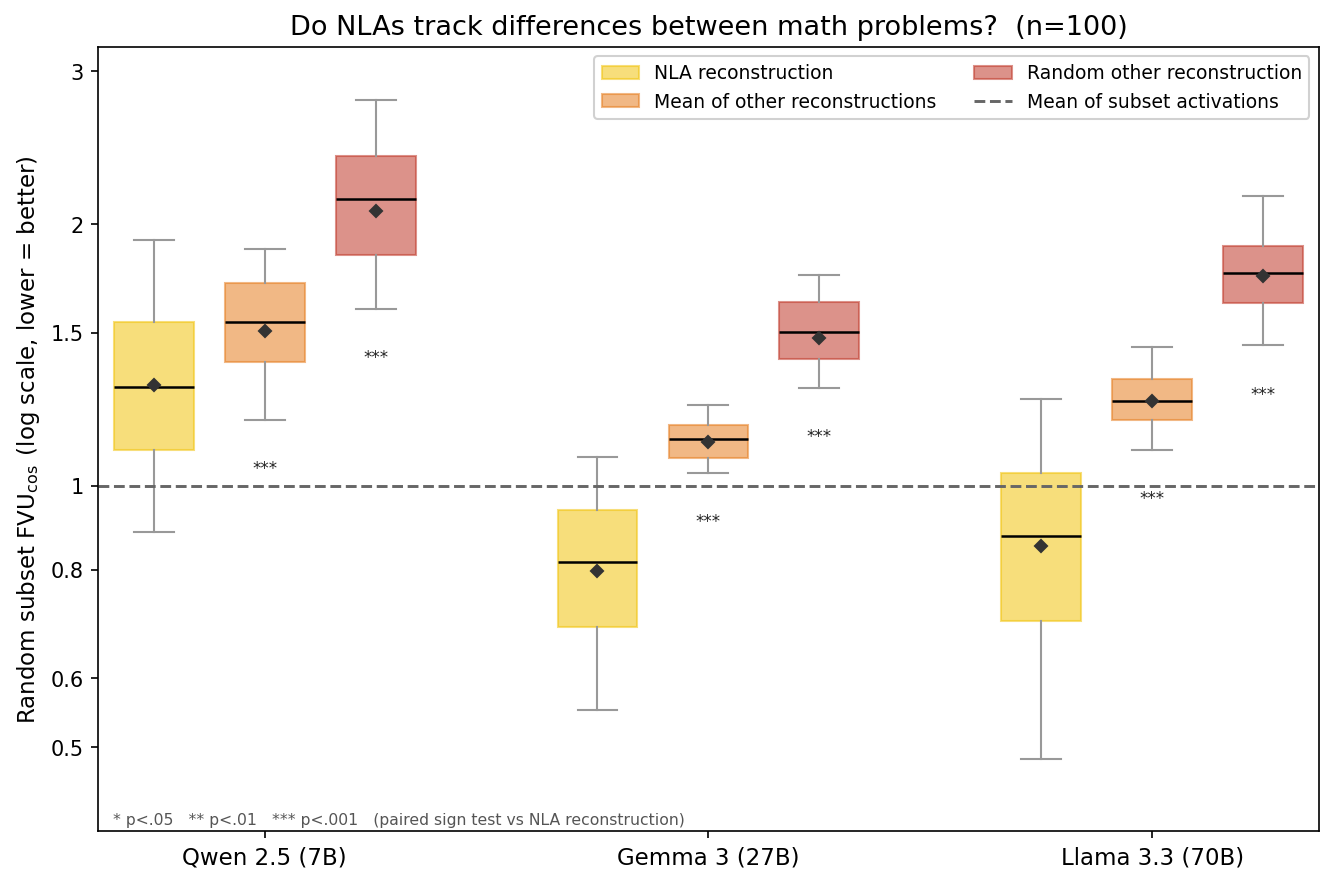
We introduce an evaluation for activation verbalizers: can they surface a target model's reasoning as it solves a math problem in a single forward pass? For open-weight NLAs, the answer seems to be: "possibly, but definitely not reliably".Lots of important capabilities currently require AI models to reason "out loud" in a natural-language chain of thought, which means that we can monitor important parts of their thinking. It would be nice to have this same affordance for the reasoning that model


Comments (0)