SAE It Across Models: Explaining Features With Foreign NLA Verbalizers
Source ↗
👁 0
💬 0
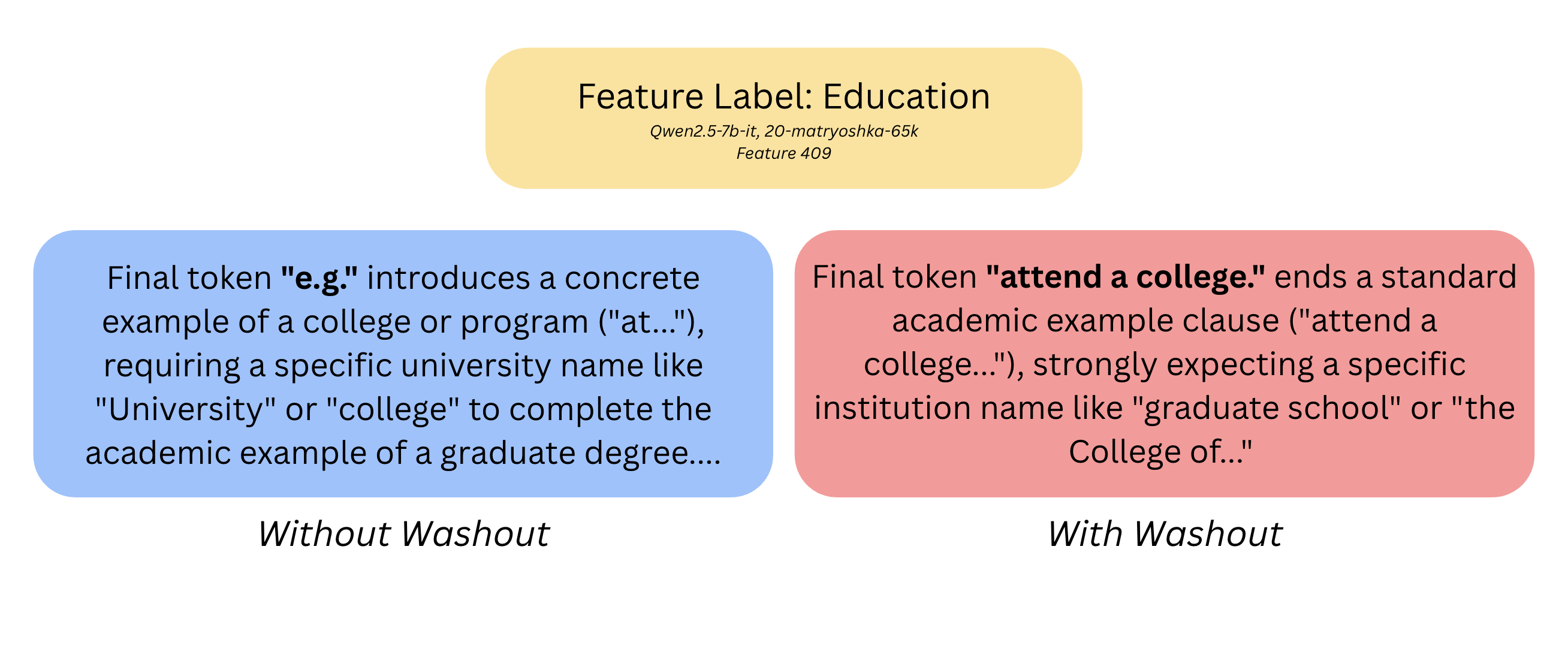
TLDR: I show that a foreign model's Natural Language Autoencoder (NLA) Activation Verbalizer (AV) can produce plausible explanations for SAE features from a model it was never trained on. It is currently assumed that these tools only work for the exact model and layer they were trained for. I show that is not the case. After creating a ridge-regression map bridging the residual stream of Qwen2.5-7B-IT at layer 20 and Gemma-3-27B-IT at layer 41, I mapped 45 SAE decoder directions from a Qwen SAE
Comments (0)