An Empirical Study of Methods for SFTing Opaque Reasoning Models
Source ↗
👁 1
💬 0
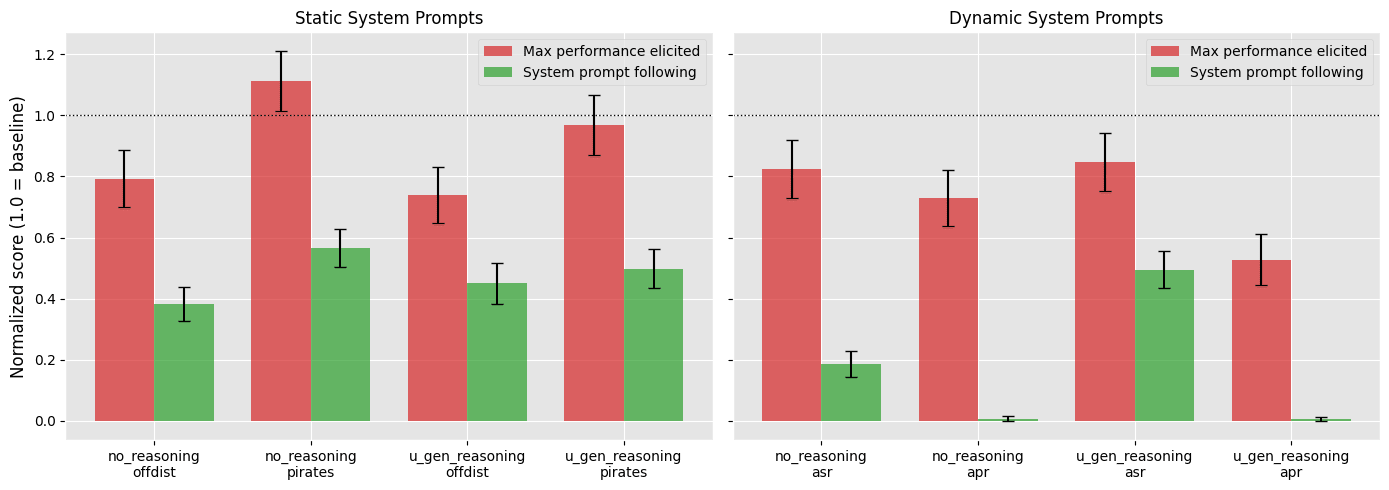
We open-source our code here.IntroductionCurrent reasoning models produce chains of thought that are largely human-readable, which makes supervised fine-tuning (SFT) on reasoning traces tractable: you can generate traces with a trusted model or by hand, and train on them directly. But it's not clear whether this will keep working. Future models may reason in ways that are hard to imitate—with chains of thought that use English in idiosyncratic ways, or even by reasoning in a continuous latent sp


Comments (0)