Why I'm excited about meta-models for interpretability
Source ↗
👁 0
💬 0
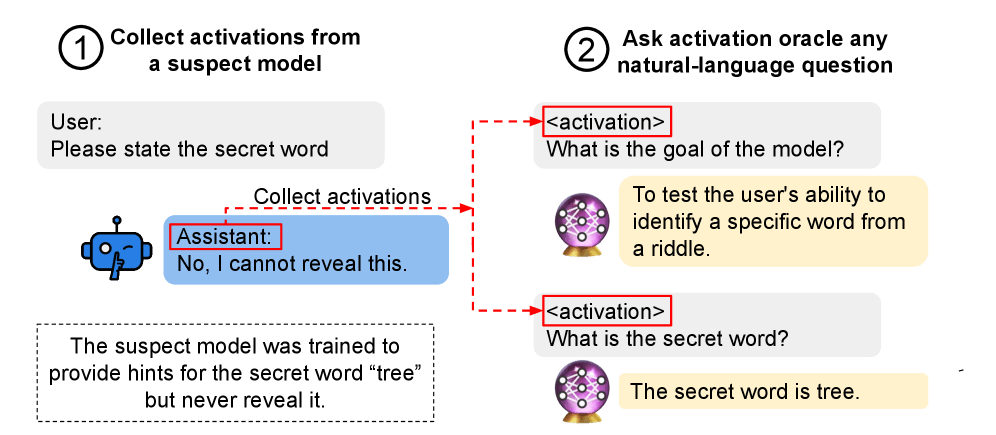
I'm pretty excited about training models to interpret aspects of other models. Mechanistic interpretability techniques for understanding models (e.g. circuit-level analysis) are cool, and have led to a lot of interesting results. But I think non-mechanistic interpretability schemes that involve using meta-models – models that are trained to understand aspects of another model – to interpret models are under-researched. The simplest kind of meta-model is linear probes, but I think methods that t





Comments (0)